How to Harness the Power of Data Management

The speed with which data is created online is difficult to fathom. Every minute online, there are 5.9 million Google searches, 66,000 Instagram photos are uploaded, and 231.4 million emails sent. According to some estimates, more than 2.5 quintillions of data are created each day. Yes, that’s quintillion, as in, 18 zeroes. All of those data points, when brought together and analyzed effectively, are powerful business currency.
Surprisingly, many organizations aren’t managing, evaluating, and using data to their advantage. In a recent survey of Fortune 1000 tech leaders, only 40% of companies said they were managing data as a business asset, and despite intentions to spend more on data management, just 24% said they have created a data-driven organization. This is the definition of missed opportunity.
The consistent and reliable flow of data across people, teams, and business functions is critical to success and the ability to innovate. And while more leaders are realizing the value of the sheer amount of data they have, they still struggle to manage and leverage that data correctly.
Opportunity knocks
When data analytics is done right, there’s much to gain, including improved efficiencies, cost reductions, informed decision-making, happier customers, and better results (to name a few!).
But challenging roadblocks often stand in the way. Sometimes, company data is coming from disparate sources, or there are too many data management tools in the tech stack to make sense of it all. Another significant issue? Many businesses lack the IT talent solution necessary to maximize data’s impact.
Databricks-skilled talent
One of the most exciting technologies embracing today’s data management hurdles and opportunities is Databricks. A data management and AI organization, Databricks streamlines the entire data management lifecycle, and its signature Lakehouse Platform is uniquely positioned to unify disparate workloads, teams, and processes.
While Databricks can have a profound impact on company results, it must be implemented by qualified technologists with Databricks-specific experience. There are several key components to learn within the Databricks platform itself so that teams can build world-class solutions, including elements like Delta Live Tables, Unity Catalog, MLflow, and of course, the foundational elements of Apache Spark.
When the right people are in place, they make sure Databricks fits into the existing tech stack, its many moving parts are orchestrated effectively, and key product benefits are being leveraged. The risk in not having Databricks experts on hand means those opportunities are missed. Even more cumbersome is the increased probability of technical debt that will require refactoring your solution down the road.
Not only can highly skilled Databricks talent help companies get it right, but they can also speed up ROI. Time-to-value is an incredibly important metric in this tech-driven business world.
How Databricks works
Implementing a technology like Databricks and maximizing its potential with the right talent are key first steps in leveraging its impact. It’s also incredibly helpful to know the basics of how the tech works. While this short explainer should get you up to speed, if you want more details, please reach out to us or review resources on the Databricks site.
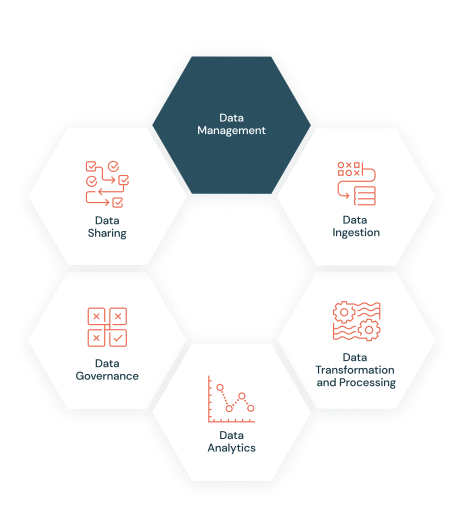
-
- Data ingestion: How the data gets into the system
It’s quite common for IT organizations to be inundated with data siloed across a wide variety of systems, databases, and more. This drives many IT teams to centralize all of their data with a Lakehouse architecture built on top of an open format storage layer, which Databricks deems a “Delta Lake.” Getting all the data into Lakehouse is critical to unify ML and analytics.
But, moving all of that very complex and disparate data into Lakehouse is a huge undertaking. There are many ways to get data into Lakehouse, but Databricks provides out-of-the-box connectors that easily integrate with data ingestion partners (i.e., Fivetran, Census), or use a tool called “Auto Loader” to easily ingest the cloud data files into the Delta Lake.
-
- Data transformation, quality, and processing: Keeping it clean
Getting all of the data into Lakehouse is a huge win, but the data must also be made usable for analysis by making sure it’s clean and reliable.
A new line of communication opens up to solve this challenge and eliminate the complexity, and that’s Databricks’ Delta Live Tables, or DLT. These give data engineering teams a scalable ETL framework to build declarative data pipelines in SQL or Python.
-
- Data analytics: Making it all make sense
Once all of that data is ready for analysis, data analysts can start to glean insights that drive actual business decisions. Speed and agility are top of mind here. Databricks SQL provides a native SQL experience that allows data analysts to simply access and query Lakehouse to perform deeper analysis.
-
- Data governance: Bringing in a simple UI
Data governance defines who has authority and control over data, and how those assets may be used. Sometimes data governance is an afterthought, but that would be a misstep. With the rapid adoption of Lakehouse, data is being more freely distributed and accessed through an organization.
To keep it all straight and effectively govern all that data, Databricks’ Unity Catalog enables data discovery, data lineage, and centralized access control so data teams can safely open Lakehouse for broad consumption. Keeping collaboration top of mind, the UI is designed so that data users will be able to document each asset and who sees it.
-
- Data sharing: What’s mine is yours
In an increasingly data-driven world, organizations must be prepared to share data across other organizations. This means with customers, partners, and suppliers, and it is a key determinant of success in gaining more meaningful insights.
But data sharing can encounter many hurdles, including a lack of standards, collaboration difficulties, or mitigating risk while sharing data. Databricks addresses these challenges with Delta Sharing, an open protocol for secure real-time data sharing that simplifies external shares.
Bringing it all together
As we move forward and shift to new ways of working, adopt new technologies, and scale operations, investing in effective data management by hiring skilled Databricks developer talent is critical to future business success.
If you’re not sure how to get started, Smoothstack can help. As a recently announced Databricks partner and Databricks consulting services provider, we are well-versed in not only how this technology works, but how to train and hire the right talent to effectively use it on the job.
No matter how far along you are in your data management journey, I hope this foundation helps you realize the vast potential for turning your data into valuable insights that drive your business forward.
Let’s Build Your Team
Connect with the Smoothstack team to learn how to close your digital skills gap with a custom-trained team.